Can ChatGPT Save Programmers?

When I was in my twenties, I smiled a lot. I didn’t know this at first, but I smiled so much that people who spent enough time with me would inevitably mention it. It was usually a compliment. Usually.
One time, a software engineer said to me, “You always seem so happy. Why?” His expression told me that it wasn’t a compliment. He looked confused, with a tinge of concern.
The question took me off guard, because as far as this person knew, I had everything to be happy about. I had just started a new job at a company I adored in a product role that fit me like a glove. All of my co-workers seemed smart and really engaged. To top it off, we were all out enjoying a company-paid department-wide dinner! It was a fun, relaxing evening after a week of intense meetings and planning. Who wouldn’t be happy?
The software engineers, that’s who.
I took a look around the room and after filtering out the exuberant executives, merry managers, and the upbeat UX designers, a new picture came into focus. A dire one.
Our most senior engineer was sitting at the bar alone, his chin resting in the palm of his hand, his elbow reddening as it bore the full weight of his head. The index finger of his free hand was picking at some invisible blemish on the glossy wooden surface of the bar. He didn’t seem so happy.
In another corner were four more engineers. They stood in a tight circle. One was gesturing with his hands, desperately trying to explain something to the others who were all impatiently waiting for him to finish so they could speak next. All of them were frowning.
I would learn later they were arguing about whether it would be more technically correct if the first row of a table in the database had an ID of 0 or 1.
It dawned on me why that engineer earlier was so incredulous about me being happy. What business does someone like me, a coder, have smiling all the time?
I’m 38 now, and I’m a father of infant twins and a three-year-old. I’m also the founder and CEO of a 30-person startup that runs a mission-critical auth service for hundreds of businesses. With all that going on, suddenly the deep crevices in my forehead, the paunchy physique, the gray hairs, and the dark circles under my eyes all seem understandable, expected even. I let people draw their own conclusions.
But the truth is that most of that wear and tear comes from one source. I still code.
Don’t get me wrong; I still love programming and always will. However, let’s just say people don’t compliment me on my cheerful demeanor anymore.
I’m not alone. A recent study by Cobalt surveyed over 600 cybersecurity and software development professionals and had some startling findings:
- 58% said they are currently experiencing burnout.
- 53% said they currently want to quit their jobs.
- 63% of respondents said their job has negatively impacted their mental health.
- 64% of respondents said their job has negatively impacted their physical health.
Thinking back to the engineers that I started with, nearly all of them are out of the day-to-day business of slinging code. In fact, more than a few have departed the world of tech entirely, opting to pursue other endeavors.
“Oh boo hoo,” you might be thinking as you play the world’s tiniest violin. “What’s so hard about sitting in a $700 chair, in front of a $3,000 MacBook Pro in your pajamas at home for 8 hours a few days a week?”
Okay, I’ll tell you.
Why Is Software Engineering So Hard?
In my experience, if you’re just in it for the money, you probably won’t be doing software engineering for very long. Most developer career tracks have hundreds of escape hatches with the same or better pay, prestige, and satisfaction.
To understand the emotional toll coding takes on a person, it’s helpful to consider the flip side of that coin: why do people persist despite the challenges? These reasons are often deeply personal and somewhat esoteric, but when you talk to enough people, recurring themes emerge.
Programming is an intensively creative process that regularly plumbs the depths of the mind and soul. The fruits of these creative efforts can be used by others in ways that the programmer could never intend or even imagine. There is perhaps nothing more pure in the human experience than making something others can appreciate and use.
No one has said it better than Frederick P. Brooks Jr., the author of “The Mythical Man Month,” a collection of essays about software engineering published in 1975. Calling them evergreen or even prescient would be underselling them. They have an almost spooky relevance. Here is my favorite excerpt from the section entitled “The Joys of the Craft.”
“There is the delight of working in such a tractable medium. The programmer, like the poet, works only slightly removed from pure thought-stuff. He builds his castles in the air, from air, creating by the exertion of the imagination. Few media of creation are so flexible, so easy to polish and rework, so readily capable of realizing grand conceptual structures…”
Brooks also describes the other side of programming. Here is an excerpt of the section called “The Woes of the Craft.”
“[To program effectively] one must perform perfectly. The computer resembles the magic of legend in this respect, too. If one character, one pause, of the incantation is not strictly in proper form, the magic doesn’t work. Human beings are not accustomed to being perfect, and few areas of human activity demand it. Adjusting to the requirement for perfection is, I think, the most difficult part of learning to program.”
This was written in 1975.
Expanding on Brooks’ words, for me, the woes and joys don’t feel so distinctly delineated. The things I’ve built that I’m most proud of are the same ones that felt like they almost killed me. The supreme joy of fixing a bug that plagued my teammates and me for years is intertwined with the feeling of infinite despair when it seemed we would never find a solution. There’s the joy and frustration of deciphering some inexplicable behavior in my program for hours, only to discover that I wrote “initializer” instead of “initialize”. These experiences have repeated endlessly over the years for most of us. It’s no wonder no one was smiling at the party.
How, after decades of exponential growth in computational power, advanced development tools, and the creation of user-friendly programming languages, do Brooks’ words still resonate today?
Conceptual Compression and The Road to AI
When I was 11 years old, I wanted to make video games.
That year, I found a book on game programming in the public library. It was called “Tricks of the Game-Programming Gurus.” The book cover resembled the box art of a DOOM-like first-person shooter, and was just about the coolest thing I ever saw. “This was it,” I thought. I took the book off the shelf and flipped to a random page. Like the cover, I remember exactly what I first saw. It was this diagram:
I flipped around the book looking for anything recognizable, anything that even looked remotely “game-like.” Nothing. I slammed the book shut and never told another soul that I wanted to be a games programmer. I was in way over my head.
But the next generation of aspiring game developers had a very different experience, thanks to conceptual compression.
Case in point: In 2015, Toby Fox, a virtually unknown 23-year-old, released a game called “Undertale,” which he coded entirely by himself on his home computer. Even though the game was self-published on the internet, it sold millions of copies and received nearly universal critical acclaim. Many publications declared it “Game of the Year,” beating Triple-A titles with massive budgets.
Undertale was made entirely in a point and click app called Game Maker Studio. This tool exemplifies the ideas of conceptual compression.
Conceptual compression is a term coined by David Heinemeier Hansson (DHH), the creator of Ruby on Rails, a web framework that undoubtedly made my entire tech career and the existence of my company, Kolide, even possible. In a nutshell, conceptual compression describes the process that led coding from binary, to more “natural” languages like Ruby, to low-code tools and LLMs.
Here is an excerpt from the blog post where Hansson coins the phrase:
“Building stuff with computers means building on top of abstractions. CPUs, 1s and 0s, assembler, C compilers, database drivers, memory management, and a million other concepts are required to make our applications work. But as we progress as an industry, fewer people need to know all of them, and thank heavens for that.
It takes hard work to improve the conceptual compression algorithms that alleviate application programmers from having to worry about the underpinnings most of the time, but it’s incredibly rewarding work. The more effectively we compress the concepts of yesterday, the lower the barriers to entry become. And we need low barriers if we are to get more people started making applications.”
Conceptual compression is what enabled Toby Fox to build Undertale and is directly responsible for the explosion of new entrants to the world of software engineering. That said, once these new people have been brought into the fold, they too must experience the delights and the woes of the craft with equal ferocity. In other words, making coding more accessible has not necessarily made it easier, at least not in terms of the mental and emotional toll it extracts.
While working on the sequel to Undertale, Toby Fox has provided numerous status updates. In them he discusses lost time trying to switch game engines, challenges on how to work with other engineers, unbearable wrist pain caused by programming, and sleep issues stemming from the length of time it’s taken to work on the game (8 years and counting).
“Can’t say [the game is] finished yet, but the unfinished parts are certainly seeming less and less numerous. That’s good because try as I might to sleep, until the game is finished, I’ll see nothing but nightmares…”
Why does conceptual compression only increase the number of folks willing to get into programming? Shouldn’t it make the experience and act of programming easier, especially for the folks who were already doing the work before a new form of compression was introduced?
This is where things get a bit confusing. It would be wrong to say these advancements don’t make programming easier. They just don’t make it easier in a way that fundamentally removes most of the toil from the process. To understand why, we must discuss the idea of the Silver Bullet, or rather the lack of one so far in software development.
Is ChatGPT a Silver Bullet for Developers?
Fred Brooks’ seminal 1986 paper “No Silver Bullet – Essence and Accident in Software Engineering” starts with a bit of a prediction, relevant to our discussion:
“Of all the monsters that fill the nightmares of our folklore, none terrify more than werewolves, because they transform unexpectedly from the familiar into horrors. For these, one seeks bullets of silver that can magically lay them to rest.
The familiar software project, at least as seen by the non-technical manager, has something of this character; it is usually innocent and straightforward, but is capable of becoming a monster of missed schedules, blown budgets, and flawed products. So we hear desperate cries for a silver bullet–something to make software costs drop as rapidly as computer hardware costs do.
But, as we look to the horizon of a decade hence, we see no silver bullet. There is no single development, in either technology or in management technique, that by itself promises even one order-of-magnitude improvement in productivity, in reliability, in simplicity.”
While I encourage you to read the essay in its entirety, a key takeaway is his discussion of different types of complexity: accidental and essential. Brooks maintains that these problems are so inherent to code-writing that no silver bullet could truly vanquish them.
Accidental Complexity: The Problems with the Tools
Accidental complexity in the context of software engineering is any complexity that is caused by the tools and abstractions we use to accomplish the work. Accidental complexity is often also called incidental complexity because it has almost nothing to do with the actual problems an engineer is trying to solve and is just an unintended side effect of the limitations of the tools we use. The programming language, the libraries, the framework, the method of testing, the web server, and the query language used on the database are all examples of accidental complexity.
It’s important to remember that “accidental” does not mean “unimportant”. Many of the woes we experience often feel related to accidental complexity engineers create for themselves.
The requirement for human perfection in programming is an example of accidental complexity and like most accidental complexity, it can be mitigated with tools and processes and perhaps even eliminated in the future. Brooks does not contest this.
Essential Complexity: The Problems with the Problem
Essential complexity in the context of software engineering is the complexity that is inextricable from the problem you are trying to solve. For example, say you want to write software that runs a ride reservation system for theme park (like Disneyland’s FastPass1.) Regardless of the programming language you use to write the software, the problem comes with its own complexity that the software must explicitly solve for it to be considered useful. We’ll explore this example in more depth later.
Essential complexity is also a major contributor to woes. Ever wonder why programmers know so many seemingly random factoids at surprising levels of depth? It’s all the essential complexity they’ve been forced to wrestle with over the years.
Most of the people who work in a Steinway piano factory probably don’t need to know how to play one. This is not the case for the programmers who are asked to create a plugin for digital audio software that simulates the sounds of a Steinway piano. To perform such a task well requires not just a fundamental understanding of how a piano works, but also a deep understanding of harmony and resonance. It even requires a mastery of things that cannot be fully known, only felt.
What is it about striking the keys on a Steinway that makes the player’s heart sing and the audience’s soul light on fire? And how does it differ from a comparable Bösendorfer or Bechstein? The programmer who wishes to make a meaningful and successful contribution to the world of digital instruments must know it all. Hence, the exhaustion. It is in essential complexity where there is also a requirement for perfection. These essential complexities must be managed perfectly in order for a true cohesive software system to emerge from “pure thought-stuff.”
Nearly all advancements in software engineering have reduced accidental complexity much more so than essential complexity. Yes, this even includes Large Language Models like ChatGPT.
Large Language Models (LLMs) work a bit like digital brains that have instant access to important information. In the best-case scenario, they’ve read everything worth reading produced by humans in books, across the internet, and even things humans wrote that were intended for computers.
Once trained, LLMs can receive prompts and reply to those prompts using probabilities. For every word or “token” (which can be a word or part of a word) they might reply with, they calculate the likelihood of it being the right next word based on all the patterns they’ve seen in text. It’s like playing a game of “what comes next?” using clues from all the data they’ve been trained on.
Depressingly, this ridiculously simple scheme is the closest thing to human intelligence we’ve ever produced as a species. The latest versions of ChatGPT can complete most high-school, college, and postgraduate level work. They can even pass the Bar exam, although this likely says more about how we test people than whether a chatbot would make a good lawyer. I certainly don’t want to live in a world where LLMs write all of our books, and I’m the first to acknowledge their limitations and potential for misuse, but it would be intellectually dishonest not to call them impressive. And their most impressive trick, at least from my perspective, is their ability to reduce both accidental and essential complexity in programming.
Due to their flexibility, LLMs are perhaps the best tool we’ve ever come up with for reducing the impact accidental complexity has on an engineer’s time. LLMs can translate code from unfamiliar programming languages into ones you understand, they can also help you develop high-level approaches to use engineering tooling you may not have encountered before, they can even help you find subtle bugs in your code that elude most compilers and linting tools.
However, unlike everything we’ve seen thus far, LLMs are also one of the first tools I’ve encountered that help reduce the burden essential complexity has on my engineering time. Let’s take our Disneyland “Fast Pass” example. What if we want to implement a similar system at our own theme park? What would we even do to approach that problem? Here is an interaction I had about this topic with ChatGPT-4.
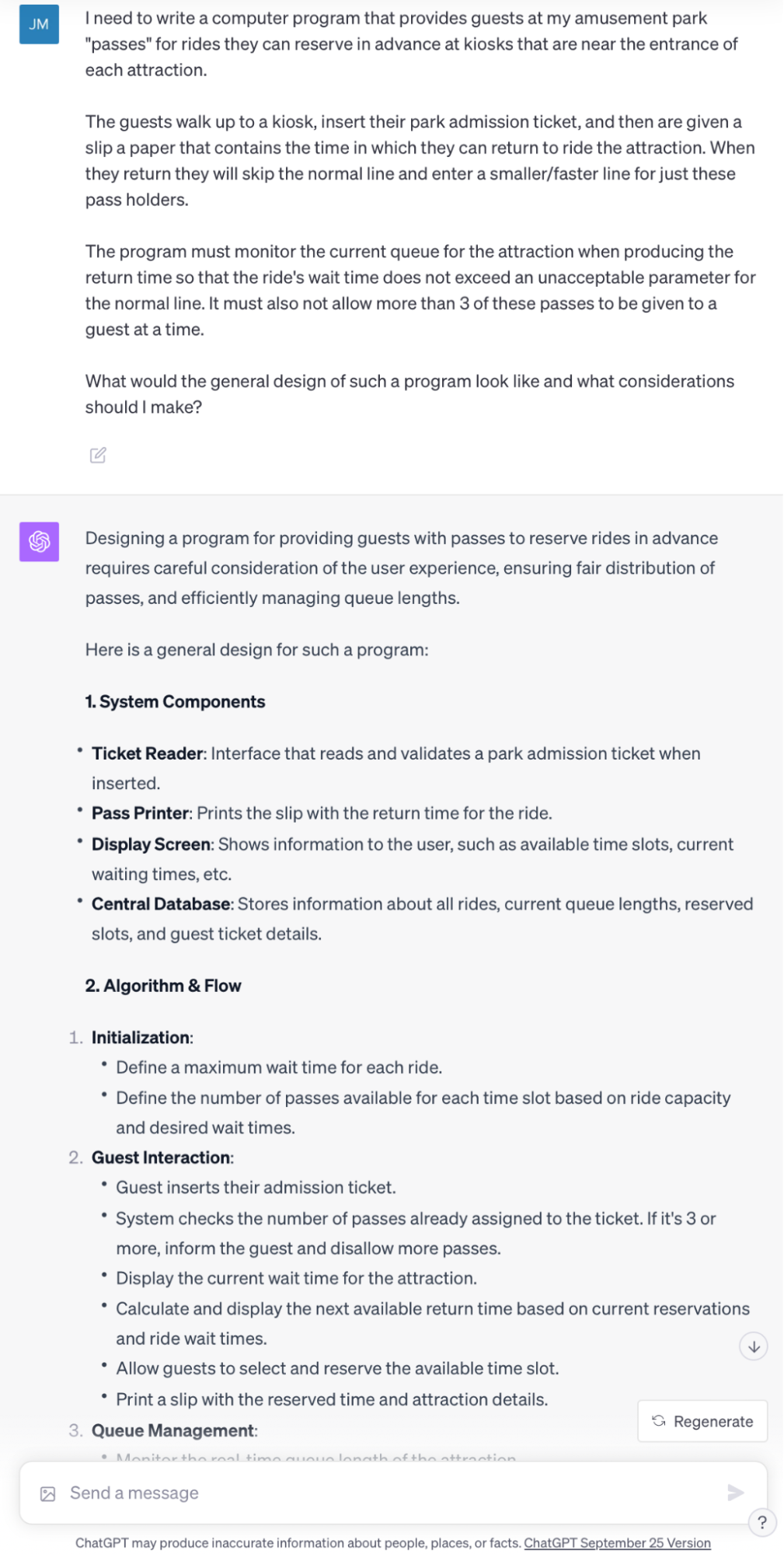
ChatGPT provides an incredibly detailed answer. That said, it’s hard to know if it’s simply regurgitating my prompt with just more extraneous words. Is there any essential complexity being solved? Let’s ask!

As someone who knows very little about the complexities of such a system, this answer is extremely helpful. I didn’t even consider the emergency handling piece. Of course, it’s possible that an engineer who specializes in park design would notice gaping holes in this answer, but still–it gave me a place to start.
With that said, this is just an enumeration of problems, not a hint of viable solutions. What does it look like if we take ChatGPT a step further and have it start producing code?
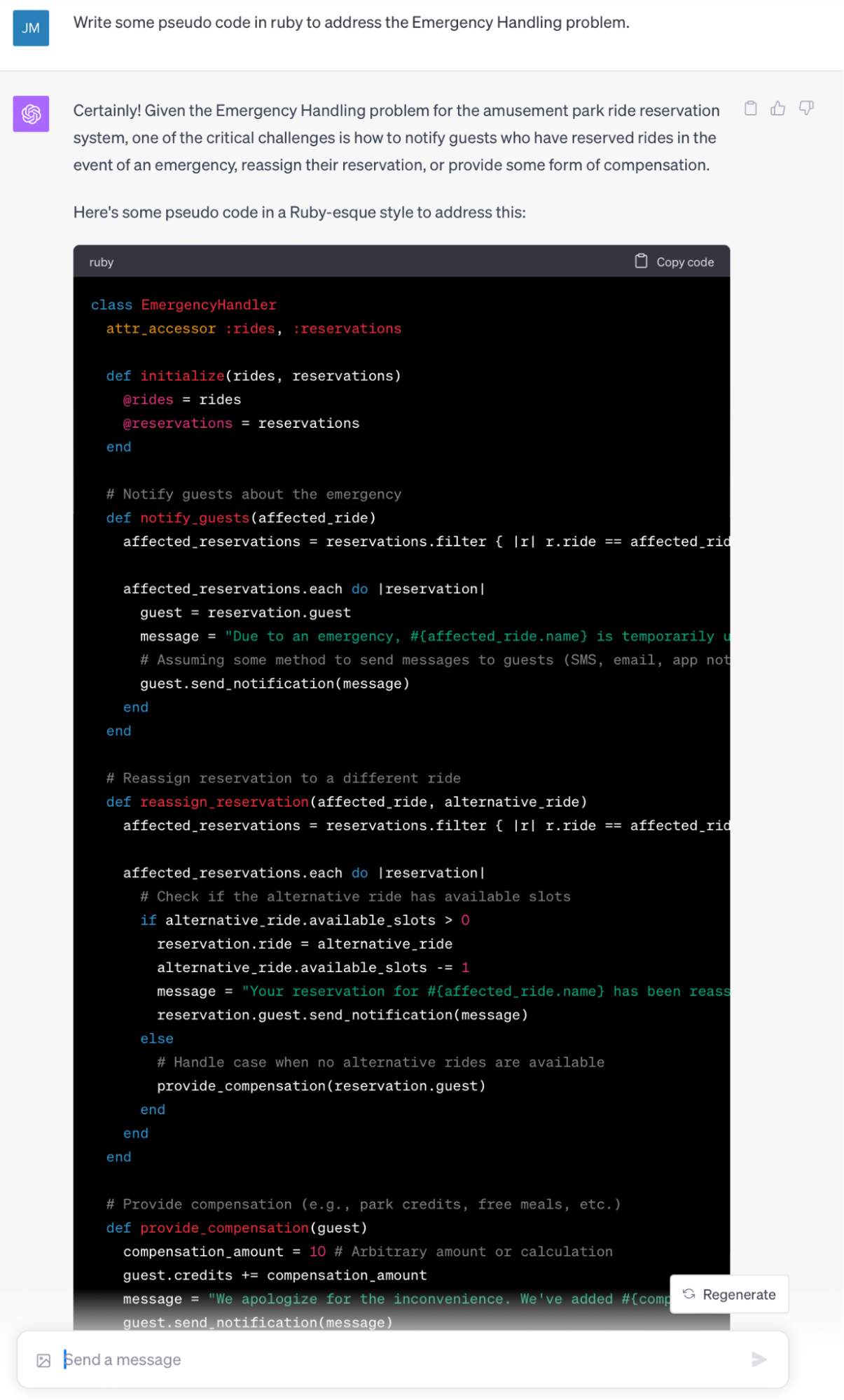
In the code, we see even further considerations for re-assigning reservations to other attractions during an attraction-specific emergency. If no rides are available, it apologizes to the customer and provides compensation. Would this be the exact code that makes it into production? No, absolutely not. Has the amount of time I’ll be spending dealing with the complexity of writing an emergency system been meaningfully reduced? Yes! A thousand times yes.
Where ChatGPT starts to break down is the enforced brevity in the inputs it can receive and the outputs it produces. At the time of this writing, ChatGPT 4 has a maximum of 8,000 tokens (roughly words) it can use to produce responses. This sounds like a lot, but when producing code, it quickly becomes a limitation, especially in situations where you need ChatGPT to produce a complete system. Try to force ChatGPT beyond this limitation with multiple prompts and you’ll find it begins to forget about essential details of requirements stated at the start of your session. It’s very much up to a human engineer to manage the “state” of the LLM to produce a large, cohesive body of work. With that said, it’s hard to imagine this limitation being one that is permanent.
ChatGPT also is limited in another, potentially unsolvable way: it occasionally produces errors. The kind of errors ChatGPT produces are often referred to as hallucinations. When an LLM hallucinates, it will make up facts on the fly or even contort base assumptions about reality that allow it to neatly answer your prompt. Surprisingly, many times when you call these errors out, ChatGPT will acknowledge and even correct them.
Much like the issue of brevity, humans can play a role in mitigating this limitation by essentially acting as a “quality control” for the outputs of LLMs. This is where LLMs become particularly perilous, especially for less experienced engineers. These engineers might have previously relied on vetting opaque code found online based on social signals such as votes on StackOverflow, stars on GitHub, upvotes on Reddit, or simply trusted recommendations from a colleague. However, this approach is not viable when dealing with an LLM. An LLM can deliver a poor recommendation with the same confidence and conviction as an excellent one.
Unlike the brevity problem, this limitation is potentially insurmountable. To many with experience using LLMs for years, it almost feels baked into the foundations of how the technology works. Expert-level human oversight of an LLM is a necessary ingredient.
When we evaluate ChatGPT performance against today’s software needs, most people want the following questions answered. As a software engineer, a product designer, a CEO of a startup, and a regular user of ChatGPT, I will do my best to answer these questions honestly.
Q: Can ChatGPT reduce the number of software engineers in total you need to hire to build and maintain a product?
A: Yes, especially for already small teams. ChatGPT dramatically reduces “accidental complexity” and meaningfully reduces “essential complexity,” which allows you to build a complete system without needing to employ as many highly-specialized experts.
Q: Will ChatGPT increase the number of engineers available to hire?
A: Yes. ChatGPT will make writing today’s applications extremely accessible to newcomers.
Q: Will ChatGPT reduce the amount of toil associated with software engineering?
A: Yes. Significantly.
So that’s the ballgame. Despite the limitations, the silver bullet for today’s software actually exists and for the first time Brooks’ cynical prediction was proven wrong.
There’s just one catch. I said ChatGPT makes writing the software of today tolerable. Who said anything about the software we need to write tomorrow?
45 Minutes of Pain: A Personal Constant
During COVID-19, many of us began working remotely. For those of us new to remote work, our commutes effectively went from long, arduous car rides (or subway in my case) to the amount of time it takes to shuffle from the bed to the computer in your underpants. My commute went from 45 minutes to 3 seconds overnight.
What did I do with all that free time? Sleep more? Relax in bed? Nope. I invented all sorts of chores and asinine tasks to fill up my morning. For instance, I began walking 45 minutes round trip to pick up a single breakfast sandwich I insisted on having every morning. When we moved, suddenly my wife and I found ourselves driving two towns over so that our children didn’t have to switch daycare providers. How long is our daily commute? You guessed it: 45 minutes.
Bruce Tognazzini, a famous usability designer who created Apple’s Human Interface Guidelines (referred to as “the HIG” by Apple developers to this day) also noticed this phenomenon. In a 1998 essay, he tied these observations to software engineering and UI design in a short essay called The Complexity Paradox. In it, he shared Tog’s Law of Commuting, which went as follows:
“‘The time of a commute is fixed. Only the distance is variable.’ Translation? People will strive to experience an equal or increasing level of complexity in their lives no matter what is done to reduce it. Make the roads faster, and people will invariably move further away.
Combine Tesler’s Law of Conservation of Complexity with Tog’s Laws of Commuting and you begin to see the 2nd order effect that we must anticipate in the future. If people will insist on maintaining equal complexity, yet we reduce the complexity people experience in a given task, people will take on a more challenging task.”
Putting my love for breakfast sandwiches and far-away daycare aside, the effect also permeates my life as a user of software.
The first time I ever opened Photoshop I was 17 years old. My father had an early digital camera (a Sony Mavica that literally burned the image directly to a mini writable CD inside the camera) and because I was basically glued to the computer 24/7 anyway, I was the obvious choice for who would be in charge of “cleaning up” the photos.
I remember the first image I loaded up. I took it by myself to test the camera. It was a closeup of me in a full body mirror. I couldn’t tell which was filthier, the mirror or me. My shirt was covered with crumbs, my face was covered in some kind of sticky gunk, I even had some gross black poppy seed stuck in my teeth. I immediately set to work in Photoshop using the recently released healing brush to make myself look even slightly presentable. After an hour or two, I was finished. It looked a little weird, but it was better than what I started with. I went to the next photo, a picture of my sister sitting on our sofa with two mildly annoyed Siamese cats on either side of her. It looked even worse. The camera captured every single strand of light gray cat hair that was all over my sister’s black pants and the brown couch. The white wall behind her lit up like she was in front of a giant lamp making her face and features impossible to see. What a mess. I gave up and told my family the photos were better if they were untouched. “It makes us look more candid,” I said. I think they bought it.
Today, when I take pictures of the family, I do most of the editing right on my phone. When I say “editing,” I essentially mean doing nothing. The photos on a modern iPhone are astonishingly good. Less time messing with photos and more time with the family, right? Wrong.
For whatever reason, I get this itch to go a little further. I import the photos into modern Photoshop and do things that would have blown my mind just two years ago. I take one photo and have Photoshop “generatively expand” the image beyond its previous dimensions, allowing an AI to predict the pixels that come next based on the pixels next to them. In another crowded photo of my wife in the middle of a city center, I’ll spend time removing literally every other person from the photo to make her look like she’s the last human on Earth.

But just like using the healing brush nearly 20 years ago, I eventually get tired of messing around with these cutting-edge tools and the complexity that comes with them. And like the healing brush of 20 years ago, they are slow, error-prone, and require multiple attempts to get just right. After two or three pictures, I usually reach my limit of frustration and find something else to do with my time.
This is Tog’s Laws of Commuting in action, and it reveals a simple and sad truth about humanity. Many of the frustrations and complications we have in our lives are not only completely self-imposed but they are also kept in constant balance by some invisible but ever-present homeostatic mechanism that guides our actions.
The essential complexity of tomorrow’s programs is inconceivable to us today and will likely only become accessible to us when we apply the full spirit of human ingenuity with the productivity gains of LLMs. Combine that truth with the zero-sum nature of most competitive markets, and we have the same recipe for human toil software engineers have faced since the dawn of computer science. We can slay all the problems we know of that lead to the woes of the craft, and inevitably we are doomed to invent new arbitrary goals that lead to new problems that recreate those same woes all over again. Two steps forward and two steps back. Hey, at least it will feel like you’re dancing.
I really hate to end on such a dour note. Even though I just said ChatGPT won’t permanently save software engineers from the emotional and physical tolls of the craft, I never said the experience of writing software had to get worse. And that’s why all of us—even and especially those of us who despise LLMs—need to start paying attention to them now while they are in their infancy and still malleable.
LLMs Are Inevitable—But We Can Influence Them
Even with their many issues, it is in our short-term and long-term best interest as engineers to embrace LLMs like ChatGPT. They make the practice of writing today’s software easier, perhaps as close to toil-free as we are ever going to get. But more importantly, as users’ needs evolve and adjust to the productivity gains we achieve with LLMs, they will become necessary to build software for tomorrow’s users and their use cases.
That doesn’t mean we need to roll over and accept all the bad that comes with LLMs. Engineers, not CEOs, will ultimately decide with their feet and their wallets how these tools integrate with our workflows, what parts of engineering we use them for, and which joyous parts we explicitly reserve for humanity.
If you are a software engineer, now is the time to work with your leadership to help them understand and embrace the use of LLMs for tasks they excel at (e.g., augmenting human engineers as they write software) and to swiftly steer them away from potential pitfalls (e.g., completely replacing human software engineers for essential tasks).
This is also the moment to establish best practices for interfacing with an LLM (e.g., insisting on explicit prompting vs. shotgun autocomplete) and to figure out how to mitigate their most significant flaws (e.g., adding social signals to suggestions to determine their quality). Furthermore, it means preparing for the arrival of junior engineers who will expect access to these tools on their first day of work.
Switching to engineering leaders, now is your time to work with engineers to embrace real and nuanced policies that accept the inevitability of LLMs but work to educate employees on their very real risks to intellectual property, security, and even their impact on programmer aptitude over time. Part of what got me thinking about this topic was a survey we ran that showed that 89% of workers regularly use AI tools, but far fewer have any defined policies for how to use them safely.
Once you have these best practices, it’s important to share them with others and in the open, so we can all learn how to accommodate this new era of AI assisted engineering tooling together. We’re working on an acceptable use policy for AI at Kolide right now, and will share the results as soon as we have them.
LLMs are not perfect, and perhaps they never can be, but their problems are familiar, and we will mitigate them. Eventually, the LLM will become an essential tool in every software engineer’s toolbelt. And yes, that toolbelt will still be firmly affixed to a real human being who, despite being paid incredibly well, probably still won’t be smiling.
-
If you are unfamiliar with FastPass, here is a nearly 2-hour exhaustive video explanation of its complicated history, including detailed information and in-depth explanations on line queuing theory. ↩