




Osquery: Under the Hood
Note: This blog is purely a primer on osquery. Go here to learn more on how osquery works with Kolide.
Eight years, 400 contributors, and 6,000 commits (and counting!) have gone into the development of osquery. It is a complex project, with performance and reliability guarantees that have enabled its deployment on millions of hosts across a variety of top companies. Want to learn more about the architecture of the system?
This look under the hood is intended for users who want to step up their osquery game, developers interested in contributing to osquery, or anyone who would like to learn from the architecture of a successful open source project.
For those new to osquery, it may be useful to start with Monitoring macOS hosts with osquery, which provides an introduction to how the project is actually used.
Query Engine
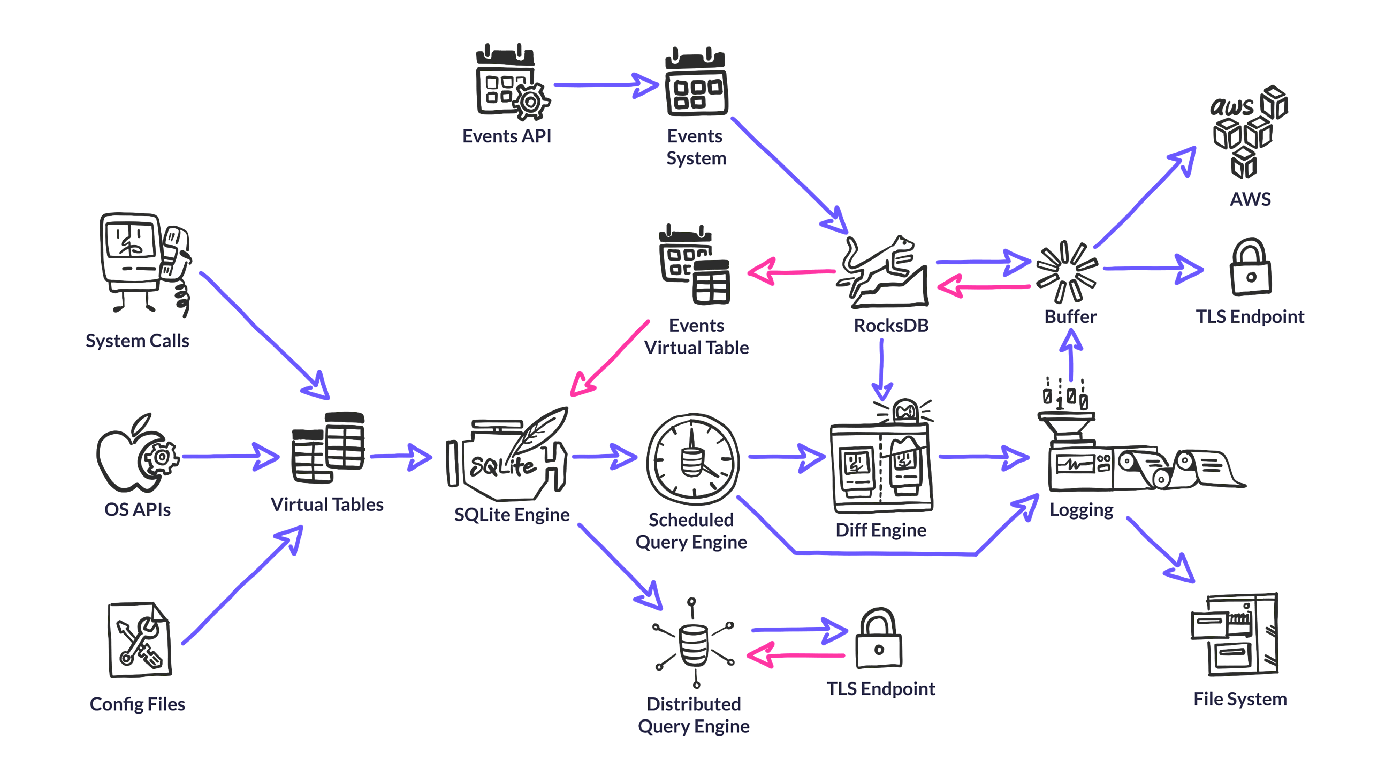
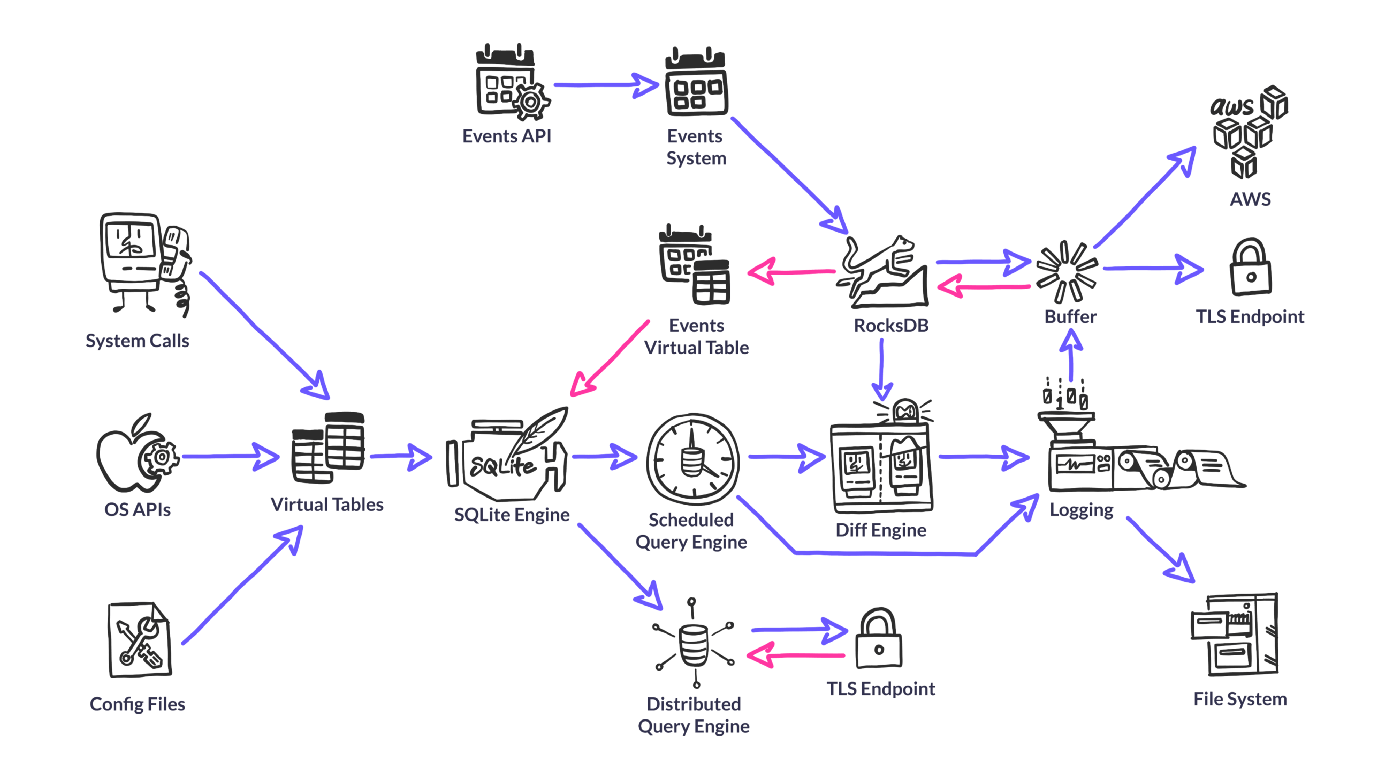
The promise of osquery is to serve up instrumentation data in a consistent fashion, enabling ordinary users to perform sophisticated analysis with a familiar SQL dialect. Osquery doesn’t just use SQLite syntax, the query engine is SQLite. Osquery gets all of the query parsing, optimization and execution functionality from SQLite, enabling the project to focus on finding the most relevant sources for instrumentation data.
Osquery doesn’t just use SQLite syntax, the query engine is SQLite.
It’s important to mention that, while osquery uses the SQLite query engine, it does not actually use SQLite for data storage. Most data is generated on-the-fly at query execution time through a concept we call “Virtual Tables”. Osquery does need to store some data on the host, and for this it uses an embedded RocksDB database (discussed later).
Virtual Tables
Virtual Tables are the meat of osquery. They gather all the data that we serve up for analytics. Most virtual tables generate their data at query time — by parsing a file or calling a system API.
Tables are defined via a DSL implemented in Python. The osquery build system will read the table definition files, utilizing the directory hierarchy to determine which platforms they support, and then hook up all the plumbing for SQLite to dynamically retrieve data from the table.
At query time, the SQLite query engine will request the virtual table to generate data. The osquery code translates the SQLite table constraints in a fashion that the virtual table implementation can use to optimize (or entirely determine) which APIs/files it accesses to generate the data.
For example, take a simple virtual table like etc_hosts.
This simply parses the /etc/hosts file and outputs each entry as a separate
row. There’s little need for the virtual table implementation to receive the
query parameters, as it will read the entire file in any case.
After the virtual table generates the data,
the SQLite engine performs any filtering provided in the WHERE clause.
A table like users can take advantage of the query context.
The users table will check if uid or username are specified in the
constraints, and use that to only load the metadata for the relevant users
rather than doing a full enumeration of users. It would be fine for this
table to ignore the constraints and simply allow SQLite to do the filtering,
but we gain a slight performance advantage by only generating the requested
data. In other instances, this performance difference
could be much more extreme.
A final type of table must look at the query constraints to do any work
at all. Take the hash table which calculates hashes of the referenced files.
Without any constraint this table will not know what files to operate on
(because it would be disastrous to try to hash every file on the system),
and so will return no results.
The osquery developers have put a great deal of effort into making virtual table creation easy for community contributors. Create a simple spec file (using a custom DSL built in Python) and implement in C++ (or C/Objective-C as necessary). The build system will automatically hook things up so that the new table has full interoperability with all of the existing tables in the osquery ecosystem.
table_name("etc_hosts", aliases=["hosts"])
description("Line-parsed /etc/hosts.")
schema([
Column("address", TEXT, "IP address mapping"),
Column("hostnames", TEXT, "Raw hosts mapping"),
])
attributes(cacheable=True)
implementation("etc_hosts@genEtcHosts")
Event System
Not all of the data exposed by osquery fits well into the model of generating on-the-fly when the table is queried. Take for example the common problem of file integrity monitoring (FIM). If we schedule a query to run every 5 minutes to capture the hash of important files on the system, we might miss an interval where an attacker changed that file and then reverted the change before our next scan. We need continuous visibility.
To solve problems like this, osquery has an event publisher/subscriber system that can generate, filter and store data to be exposed when the appropriate virtual table is queried. Event publishers run in their own thread and can use whatever APIs they need to create a stream of events to publish. For FIM on Linux, the publisher generates events through inotify. It then publishes the events to one or more subscribers, which can filter and store the data (in RocksDB) as they see fit. Finally, when a user queries an event-based table, the relevant data is pulled from the store and run through the same SQLite filtering system as any other table results.
Scheduler
Some very careful design considerations went into the osquery scheduler. Consider deploying osquery on a massive scale, like the over 1 million production hosts in Facebook’s fleet. It could be a huge problem if each of these hosts ran the same query at the exact same time and caused a simultaneous spike in resource usage. So the scheduler provides a randomized “splay”, allowing queries to run on an approximate rather than exact interval. This simple design prevents resource spikes across the fleet.
It is also important to note that the scheduler doesn’t operate on clock time, but rather ticks from the running osquery process. On a server (that is never in sleep mode), this will effectively be clock time. On a laptop (often sleeping when the user closes the lid), osquery will only tick while the computer is active, and therefore scheduler time will not correspond well with clock time.
Diff Engine
In order to optimize for large scale and bubble up the most relevant data, osquery provides facilities for outputting differential query results. Each time a query runs, the results of that query are stored in the internal RocksDB store. When logs are output, the results of the current query are compared with the results of the existing query, and a log of the added/removed rows can be provided.
This is optional, and queries can be run in “snapshot” mode, in which the results are not stored and the entire set of query results are output on each scheduled run of the query.
RocksDB
Though much of the data that osquery presents is dynamically generated by the system state at query time, there are a myriad of contexts in which the agent stores data. For example, the events system needs a backing store to buffer events into between intervals of the queries running.
To achieve this, osquery utilizes another Facebook open source project, RocksDB. This is a highly write-optimized, embedded key-value database that is compiled into the osquery binary.
RocksDB is used for storing events, results of scheduled queries for differential logging, configuration state, buffered logs, and more.
For more on RocksDB and osquery, check out the Facebook Engineering Blog.
Configuration Plugins
In the multitude of environments osquery runs in, it may need to pull configuration from a variety of sources. To support this, there is a concept of Configuration Plugins that provide the necessary configuration to the daemon. Common sources for configuration are the filesystem (config files laid down by Chef, Puppet, etc.), or via a TLS server.
Config plugins conform to the following API (in Go syntax):
func GenerateConfigs(ctx context.Context) (map[string]string, error)
A config plugin will return osquery configuration (in JSON form) when called by the extension manager. This configuration will then be passed to the osquery daemon.
Logger Plugins
Like configuration, logging must also be compatible with a variety of architectures. Commonly used logging plugins are filesystem (often forwarded with an agent like splunkd or logstash), TLS, or AWS Kinesis/Firehose.
Logger plugins conform to the following API (in Go syntax):
func LogString(ctx context.Context, typ logger.LogType, logText string) error
Whenever osquery generates logs (status or result logs), these will be written to the logger plugin which can then process the logs in any way necessary.
Distributed Plugins
Distributed plugins enable remote live querying of data from osquery. The only existing implementation of the distributed plugin is TLS. Unlike config and logger plugins, this is not an essential part of the osquery system, but it does enable the nice feature of live queries (as seen in Kolide Fleet).
Distributed plugins conform to the following API (in Go syntax):
func getQueries(ctx context.Context) (*distributed.GetQueriesResult, error)
func writeResults(ctx context.Context, results []distributed.Result) error
These APIs allow the osquery process to retrieve queries to execute from some out-of-process controller, and then write results to that controller.
Static Compilation
To ease the burden of deployment on a wide array of endpoints, osquery builds into a single executable, with most of its dependencies statically linked. This executable includes osqueryi and osqueryd, along with all of the built-in plugins that enable a full osquery deployment.
Because osquery is a C++ project with a large number of dependencies, building a static binary is a nontrivial problem. The osquery developers have done an amazing job of creating a build system that will pull all of these dependencies and build the static executable. The resulting binary needs only some basic shared libraries that are available on almost any system, while the more exotic dependencies are included.
Watchdog
To ensure that runaway queries never cause too much impact on system performance, osqueryd has a “Watchdog” that spawns a “worker” osquery process. This Watchdog process keeps tabs on the queries that are executing, and kills the worker process if it exceeds the predefined performance thresholds. Additionally, it can blacklist queries that are consistently causing performance problems, allowing users to return and debug these queries at a later time while addressing the immediate problem.