The File Table: Osquery's Secret Weapon
With Great Power Comes Great Responsibility

This article is part of an ongoing series in which we look at specific osquery tables and discuss what they can and cannot do. In another article: Using Spotlight across your fleet with osquery, we discussed a method for finding files on macOS computers that was incredibly performant and could find files based on the content and metadata inside.
The usage of Spotlight in that example was predicated on its ability to index
text contents in files and its ability to avoid the performance hit
of recursive filesystem searching. We briefly touched on the limitations of
the file table in that article, and here we will take a slightly deeper dive.
This post will look at a cross-platform alternative to finding files across your infrastructure.
The File Table in Osquery
The file table in osquery has an
incredible degree of utility across many queries and represents a
fundamental cornerstone of osquery’s core capabilities.
Let’s start by taking a look at its basic schema:
+---------------+---------+---------------------------------------+
| COLUMN | TYPE | DESCRIPTION |
+---------------+---------+---------------------------------------+
| path | TEXT | Absolute file path |
| directory | TEXT | Directory of file(s) |
| filename | TEXT | Name portion of file path |
| inode | BIGINT | Filesystem inode number |
| uid | BIGINT | Owning user ID |
| gid | BIGINT | Owning group ID |
| mode | TEXT | Permission bits |
| device | BIGINT | Device ID (optional) |
| size | BIGINT | Size of file in bytes |
| block_size | INTEGER | Block size of filesystem |
| atime | BIGINT | Last access time |
| mtime | BIGINT | Last modification time |
| ctime | BIGINT | Last status change time |
| btime | BIGINT | (B)irth or (cr)eate time |
| hard_links | INTEGER | Number of hard links |
| symlink | INTEGER | 1 if the path is a symlink, else 0 |
| type | TEXT | File status |
| attributes | TEXT | File attrib string. |
| volume_serial | TEXT | Volume serial number |
| file_id | TEXT | file ID |
+---------------+---------+---------------------------------------+
As we can see, there are many metadata attributes that we can use to our advantage both when building queries and refining results. Let’s run a sample query against the file table to inspect a file on our local device:
SELECT *
FROM file
WHERE path = '/Users/fritz-imac/Downloads/github-recovery-codes.txt';
This query returns the following data:
path = /Users/fritz-imac/Downloads/github-recovery-codes.txt
directory = /Users/fritz-imac/Downloads
filename = github-recovery-codes.txt
inode = 20650405
uid = 502
gid = 20
mode = 0644
device = 0
size = 206
block_size = 4194304
atime = 1533646421
mtime = 1532976585
ctime = 1532976860
btime = 1532976585
hard_links = 1
symlink = 1
type = regular
Very cool! We can see that we have a fair bit of information about
this github-recovery-codes.txt file. Now, let’s take a moment to
clean it up and return the values in a format that we can quickly parse.
Osquery, by default, returns some data in a less than humanly digestible format.
- Time is represented in UNIX epoch
- Size is defined in bytes.1
Unix epoch date-times are great because they are the easiest to transform. Using the datetime(value,'unixepoch')
syntax, we can convert any date-time result in osquery to an easier read value.
Then, we will round our size from bytes to megabytes
using the ROUND function ROUND((f.size * 10e-7),4)
Finally, we will join our uid and gid on their respective tables (users and groups)
and return their actual names. Let’s try it below:
SELECT
f.path,
u.username AS file_owner,
g.groupname AS group_owner,
datetime(f.atime, 'unixepoch') AS file_last_access_time,
datetime(f.mtime, 'unixepoch') AS file_last_modified_time,
datetime(f.ctime, 'unixepoch') AS file_last_status_change_time,
datetime(f.btime, 'unixepoch') AS file_created_time,
ROUND(
(f.size * 10e - 7),
4
) AS size_megabytes
FROM
file f
LEFT JOIN users u ON f.uid = u.uid
LEFT JOIN groups g ON f.gid = g.gid
WHERE
path = "/Users/fritz-imac/Downloads/github-recovery-codes.txt"
Running this query results in the following output:
path = /Users/fritz-imac/Downloads/github-recovery-codes.txt
file_owner = fritz-imac
group_owner = staff
file_last_access_time = 2018-08-29 18:43:40
file_last_modified_time = 2018-07-30 18:49:45
file_last_status_change_time = 2018-07-30 18:54:20
file_created_time = 2018-07-30 18:49:45
size_megabytes = 0.0002
Already that is much easier to read! Now we can go hunting for any file we want.
But wait, slow down, tiger, there is a big caveat with the file table in osquery.
You Have to Know Where Your File Is First!
Unfortunately, the file table requires a WHERE clause, meaning that you
need to know roughly where an item is before you can go querying for it.
This protects against the massive recursion that would be necessitated by
searching every single directory and their respective subdirectories on the
file system.
The clause WHERE path = can thankfully be massaged through the use of
wildcards and a LIKE argument, e.g., WHERE path LIKE "/foo/%" but there are
some tricky things to look out for in terms of the way wildcards are handled!
Understanding How Single Wildcards ‘%’ Work Within the File Table
SELECT * FROM file WHERE path LIKE "/%";
Single wildcards treat the file table like an ogre in that it’s like an onion. They all have layers
A single % in the file table allows you to find items in a
specified layer of the file system. For instance:
SELECT
*
FROM
file
WHERE
path LIKE "/Users/%/Google Drive/%/%";
This query would find any files that were located within directories like:
/Users/username/Google Drive/foo/bar/
/Users/username2/Google Drive/bar/foo/
It will not, however, return any files that were located subsequent subdirectories deeper. For instance:
/Users/username/Google Drive/foo/bar/baz/filename.ext
/Users/username/Google Drive/foo/bar/baz/qux/quux/filename.ext
This means you can’t print out every file on your file system by running:
SELECT
*
FROM
file
WHERE
path LIKE "/%"
Because as long as you only use single % wildcards, you will only ever be
able to see all files at that layer of the subdirectory hierarchy.
So in this instance, the first layer, items in the root directory:
osquery> SELECT path, btime, size, type FROM file WHERE path LIKE "/%";
+----------------------------+------------+------+-----------+
| path | btime | size | type |
+----------------------------+------------+------+-----------+
| /Applications/ | 1508949222 | 4114 | directory |
| /Library/ | 1508949320 | 2312 | directory |
| /Network/ | 1469907150 | 68 | directory |
| /System/ | 1508949086 | 136 | directory |
| /Users/ | 1469911752 | 170 | directory |
| /Volumes/ | 1469907156 | 136 | directory |
| /bin/ | 1508949475 | 1292 | directory |
| /cores/ | 1469907149 | 68 | directory |
| /dev/ | 0 | 4444 | directory |
| /etc/ | 1508949384 | 4114 | directory |
| /home/ | 0 | 1 | directory |
| /installer.failurerequests | 1504228163 | 313 | regular |
| /net/ | 0 | 1 | directory |
| /private/ | 1519081368 | 204 | directory |
| /sbin/ | 1508949475 | 2142 | directory |
| /tmp/ | 1519081368 | 1326 | directory |
| /usr/ | 1508948533 | 306 | directory |
| /var/ | 1510954365 | 986 | directory |
+----------------------------+------------+------+-----------+
Understanding How Double Wildcards ‘%%’ Work Within the File Table
To recursively search your filesystem, you can use %% the double wildcard.
-- WARNING: Do NOT run the following query it will literally return thousands of
-- files on your computer!!!
SELECT
*
FROM
file
WHERE
path LIKE "/%%"
Double wildcards can only ever be used at the end of a string eg. /foo/bar/%%
Double wildcards can NEVER be used mid-string (infix)
This means the following query will never return results:
SELECT
path
from
file
WHERE
path LIKE "/Users/%%/UX/%%";
However, you can use the double wildcard to your advantage in limited situations where you want to search within a known parent directory and its respective sub-directories. The more possible sub-directories and recursion, the slower and less performant the query will be.
SELECT
path
FROM
file
WHERE
path LIKE "/Users/fritz-imac/Google Drive/UX/%%";
Mixing single ‘%’ and double wildcards ‘%%’ within the file table
The last fun thing you can do is mix wildcard types if you want to restrict
certain parts of your WHERE clause to a specific layer and permit recursion
at another part of the path.
For instance, if I wanted to see how much percentage of disk space the files located in Google Drive are using per device across my entire fleet, I could run the following query:
SELECT SUM(file.size) AS gdrive_size,
(SELECT (mounts.blocks * mounts.blocks_size)
FROM mounts
WHERE PATH = '/') AS total_disk_size,
(100.0 * SUM(file.size) /
(SELECT (mounts.blocks * mounts.blocks_size)
FROM mounts
WHERE PATH = '/')) AS gdrive_percentage_used
FROM FILE
WHERE file.path LIKE '/Users/%/Google Drive/%%';
Which produces the following output:
+-------------+-----------------+------------------------+
| gdrive_size | total_disk_size | gdrive_percentage_used |
+-------------+-----------------+------------------------+
| 7492526705 | 379000430592 | 1.97691772890512 |
+-------------+-----------------+------------------------+
These queries can be run, but you need to be mindful of how many files your system is looking through to produce the end result.
Limitations of Wildcard LIKE Searches in the File Table
While undeniably useful, the file table is not without limitations. Knowing
what those limitations are and how to avoid them will help you make sure you are
returning your expected data and that it is accurate.
It is worth noting that both of these limitations are outlined in a GitHub issue, in the osquery repository #7306, and may someday be addressed.🤞🏻
Symlink loops may prevent complete recursive crawling
If you were to run a query like:
SELECT * FROM file WHERE path LIKE '/%%'
You might expect that it would return every file on your file-system, but in
practice it does not. This is because osquery will end the query once it
encounters something called a symlink loop.
osquery> SELECT COUNT(*) FROM file WHERE path LIKE '/%%';
+----------+
| COUNT(*) |
+----------+
| 1172 |
+----------+
Symlinks (also known as symbolic links) are frequently referred to as shortcuts. They are files which point to another file or folder on the computer.
A symlink loop is when a symlink points back to a parent directory in its path which creates an infinite loop if traversed. We can observe this behavior in practice by querying a folder which contains one of these loops:
As we can see in the screenshot below, the directory /tmp/directory-level-0/
consists of 6 nested folders.
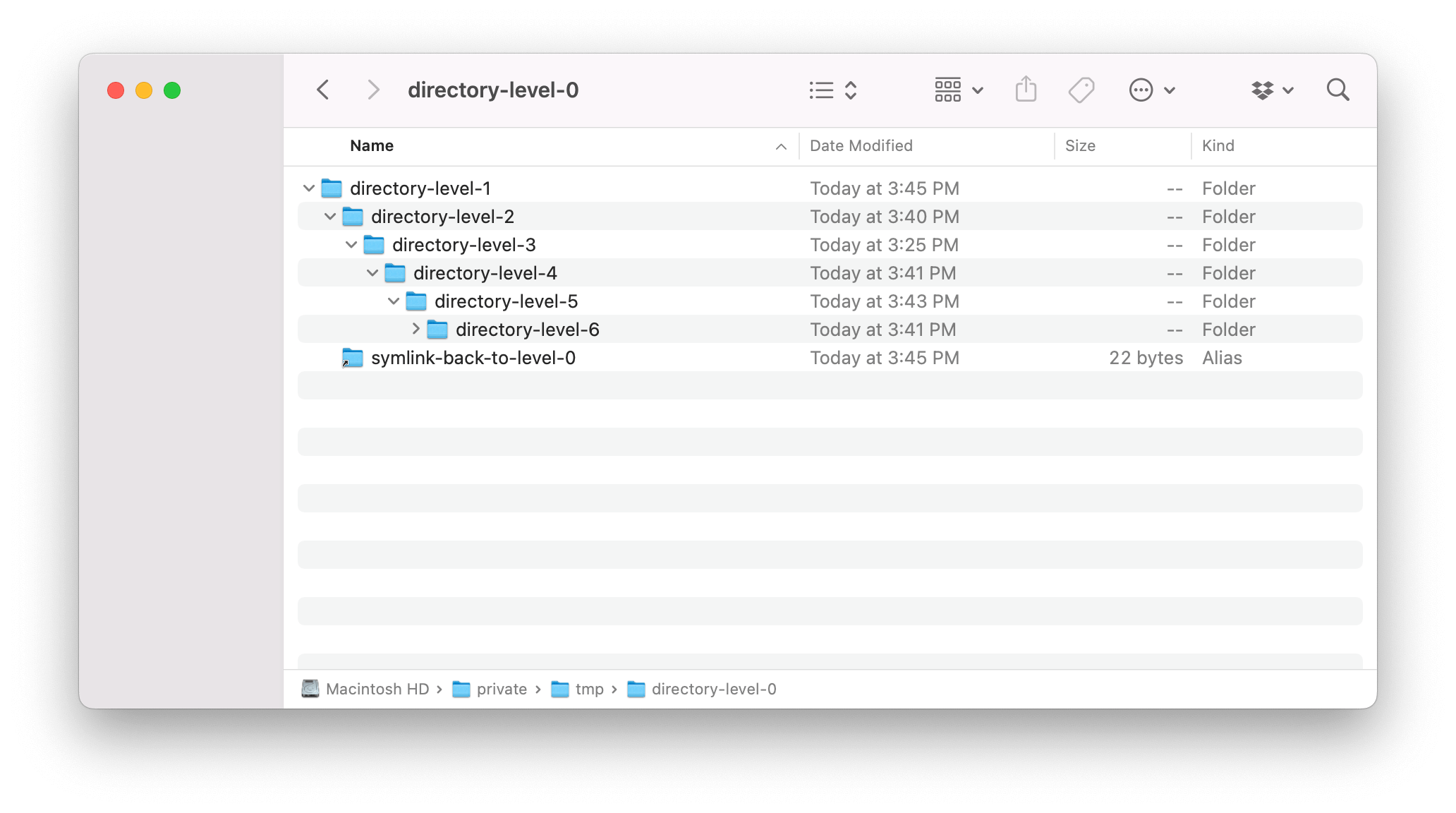
The tree command shows the expected output of our nested directories:
➜ directory-level-0 tree
.
└── directory-level-1
├── directory-level-2
│ └── directory-level-3
│ └── directory-level-4
│ └── directory-level-5
│ └── directory-level-6
└── symlink-back-to-level-0 -> /tmp/directory-level-0
However, when we recursively query the parent folder using osquery, we receive an incomplete result. This is because the symbolic link is causing a recursive loop of a child pointing back to a parent which osquery avoids by preemptively terminating the query:
osquery> SELECT path FROM file WHERE path LIKE '/tmp/directory-level-0/%%';
+-------------------------------------------------------------------------------------+
| path |
+-------------------------------------------------------------------------------------+
| /tmp/directory-level-0/directory-level-1/ |
| /tmp/directory-level-0/directory-level-1/directory-level-2/ |
| /tmp/directory-level-0/directory-level-1/directory-level-2/directory-level-3/ |
| /tmp/directory-level-0/directory-level-1/symlink-back-to-level-0/ |
| /tmp/directory-level-0/directory-level-1/symlink-back-to-level-0/directory-level-1/ |
+-------------------------------------------------------------------------------------+
Unfortunately, the recursive searching in the osquery file table is
accomplished via glob which has no method for skipping over symlinks.
As a result you have to take a targeted approach when recursively searching using double wildcards to avoid recursing through paths that may contain symlinks.
Hidden files are not returned by recursive searches
If a file is marked as hidden in the file-system (typically by prepending the
filename with a .), it will not be returned in the results of any recursive
file search. This can be observed in the following example query:
osquery> SELECT * FROM file WHERE path LIKE '/Users/test-macbook/git/kolide/test/%' AND filename = '.git';
osquery>
osquery> SELECT path FROM file WHERE path = '/Users/test-macbook/git/kolide/test/.git';
+------------------------------------------+
| path |
+------------------------------------------+
| /Users/test-macbook/git/kolide/test/.git |
+------------------------------------------+
osquery> SELECT path FROM file WHERE directory = '/Users/test-macbook/git/kolide/test' AND filename = '.git';
+------------------------------------------+
| path |
+------------------------------------------+
| /Users/test-macbook/git/kolide/test/.git |
+------------------------------------------+
Keep this in mind if you are searching for files that might be marked as hidden in the filesystem. Otherwise, you may be missing results you might have expected.
When Should I Use Recursive Queries in the File Table in Osquery?
When there is literally no other option for locating a file of import.
When you can limit the degree of recursion that your search is capable of by scoping it to a particular folder, e.g., (
'/Users/%/Downloads/%%')
If there is ever any doubt on how expensive a query is after you schedule it, osquery comes with great tools to do this analysis. For example, in a product like Kolide, you can run a live query against your devices that enumerates all of the queries in your schedule by simply running:
SELECT * FROM osquery_schedule
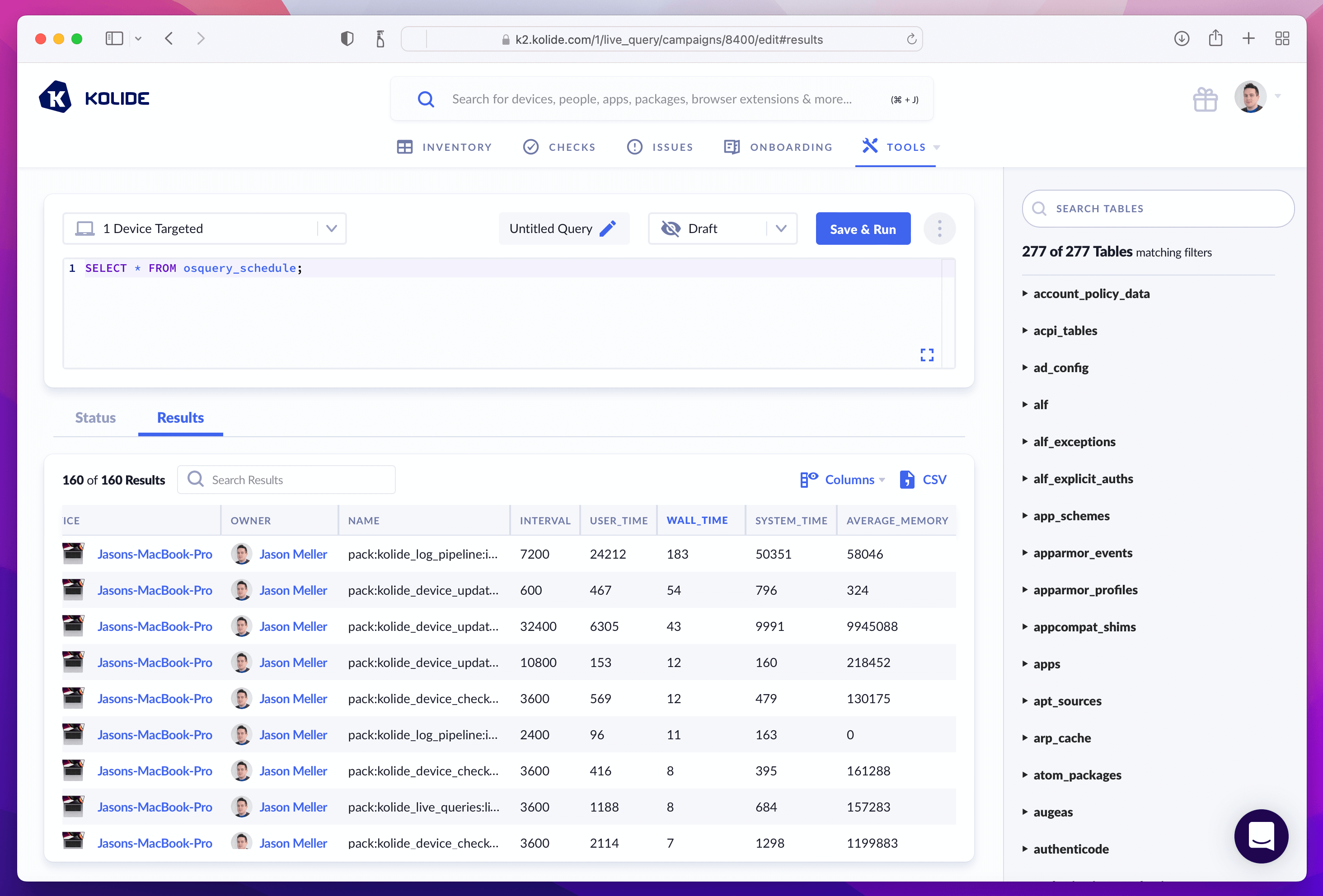
In this screenshot, we can short all the queries in our schedule by the wall_time
to get a sense of how long these take to complete. We can even see how much
memory they may be using during execution. These are all indicators that we may
execute file queries with too much recursion potential.
If you’d like to read more osquery content like this, sign up for our biweekly newsletter.
-
Osquery sizes are returned in bytes but some comp-sci items (RAM vs Hard Drives) calculate their size in base-10 and some calculate in base-2 ↩