The Real-World Challenges of Patch Management

In theory, patch management should be trivially easy for a company to manage. An IT team–potentially helped by an MDM, a dedicated patch management tool or an MSP–tests and deploys patches, every endpoint gets updated at roughly the same time, and users are barely aware it’s happening at all.
Most articles about patch and vulnerability management describe this idealized flow as if it represents the real world.

But the situation looks a little different on the ground.

In reality, IT teams are constantly battling a never-ending torrent of updates and constantly falling behind; Security Navigator’s research shows that businesses still take an average of 215 days to patch a known vulnerability.
In vulnerability management, the stakes for just a single error can be monumental. In a Ponemon Institute study, 42% of organizations that suffered a data breach reported it “occurred because a patch was available for a known vulnerability but not applied.”
Clearly, patch management is harder than it looks. It’s a messy process in which there are often as many exceptions and edge cases as there are rules, and any workflow must balance competing pressures from IT, Security, management, and end users.
Furthermore, “patch management” encompasses a huge range of issues, including:
- OS updates
- OS upgrades (which turns out to be a pretty big distinction, especially for Macs)
- Browsers
- Other third-party software
There are different tactics for dealing with each of these, and they also vary depending on whether you’re talking about macOS, Windows, Linux, mobile devices, servers, etc.
We’ll tackle each of those topics in detail in other blog posts, but here, we’re going to take a high-level look at why the patch management process is so painful, the limits of automation, and what’s missing from the accepted list of past management best practices.
What is Patch Management?
Patch management refers to the practice of updating software to fix bugs, address security issues, and add new features. The term is sometimes used interchangeably with “vulnerability management,” but is really a subset of it, and only makes up one part of a comprehensive risk mitigation strategy.
From an IT perspective, the security angle of patch management is by far the most important, since any time a vendor announces they’re plugging a vulnerability, hackers race to exploit it on any machine that hasn’t downloaded the patch yet.
The term “patch management” applies to both a device’s operating system and firmware and third-party applications, though IT professionals often use it to only mean one or the other. (That’s why when an IT pro tells you they’ve got patch management under control, it’s a good idea to ask what they mean, because they’re usually not including third party apps in their definition.)
The role of auto-updating apps
Over the years, many vendors have tried to make patching as frictionless as possible for users. “Evergreen apps” manage their own updates with little or no user interaction. However, the difference between “little” and “no” user interaction turns out to be extremely problematic.
For example, Google Chrome–the app I’m using to write this blog–will update automatically the next time I restart it. But truthfully, I don’t restart Chrome (or my laptop) nearly as often as I should. Left to my own devices, I’ll click “remind me later” until I literally have no other choice.
And since I’m on a Mac, IT has a very limited ability to force me to update, other than sending me increasingly annoying “nudges” via MDM. (There is actually a better way to enforce updates on your Mac fleet, but we’ll get to that later.)
Why Enterprise Patch Management is So Hard
Patch management in a business setting presents a whole array of challenges, even beyond the technical challenges of deploying multiple types of updates to multiple types of devices. Organizations face more pressure than individuals to keep up with patching because they’re bigger targets for hackers, and an updated fleet may be required to meet their legal and compliance obligations.
Yet IT teams must balance urgency with caution, because patching can introduce new problems. For one thing, updates can be incompatible with existing software and/or hardware. In 2020, Apple disabled kernel extensions in macOS Big Sur which effectively disabled VPNs and some other security tools. In situations like that, an enterprise needs to defer the upgrade until either Apple or their VPN can adapt. But to complete the catch-22, critical security patches might be gated behind these major upgrades, so enterprises can’t put them off indefinitely.
All this to say that even if there were a magic button that could deploy every update as soon as it’s released (and there emphatically isn’t), managing patches while minimizing disruption would still take significant human oversight.
And it just gets more complicated from there.
Employee disruption leads to exceptions
One dirty little secret of IT is that the devices with the most unpatched vulnerabilities often belong to people near the top of the org chart. The reason for that is simple: those are the people with enough clout to demand that they be exempt from automated reboots.
To be fair, there are valid reasons for exceptions aside from “they’re annoying,” but the fact remains that every machine that isn’t included in the patch management process is an open door for hackers.
This problem is endemic; according to an Ivanti survey, “61% of IT and security professionals said that line of business owners ask for exceptions or push back maintenance windows once a quarter because their systems cannot be brought down.”
Work from home/ BYOD policies
The shift to remote work has created or exacerbated several problems with patch management. In particular, WFH has increased the Shadow IT problem, since you can’t patch what you can’t see.
When the COVID lockdowns started, many employees started working on their personal (meaning unmanaged) computers, which IT teams have no way to remotely patch. As Stephen Boyer, CTO and co-founder of BitSight, said at the start of the pandemic, “if you’re expecting [employees] to use their own computers for work, you’re going to have to have a lot of nerve to tell them what they can and can’t run on their own computers.”
This phenomenon led to the LastPass hack, one of the most reputation-ruining data breaches in recent years. In this case, a hacker targeted a LastPass engineer’s home computer via an outdated version of Plex, a media player. The patch for this exploit had been available for three years, but in all likelihood, the computer wasn’t managed via MDM, so IT would have no way of knowing about this lurking threat.
Lack of IT bandwidth
The average IT team simply can’t keep up with the volume of patches that come from vendors every month. The NIST reported that over 20,000 new vulnerabilities were discovered in 2021 alone, and prioritizing, testing, and deploying even a fraction of that number is a Herculean (or perhaps Sisyphean) task.
Some companies augment their in-house IT with Managed Service Providers (MSPs) or Managed Security Service Providers (MSSPs), but even then it’s hard to keep up. In fact, a recent argument in patch management discourse (yes, it’s a thing), is that companies should stop trying to patch everything and focus on triaging the most critical patches on the most important apps. Unfortunately, that’s probably true, even though the LastPass breach proved that an application doesn’t have to be mission critical to be a devastating attack vector.
So how should you prioritize patches?
For what it’s worth, there are effective ways of prioritizing patches so you get to the most dangerous issues without fatiguing end users or IT. At Kolide, we create and deploy checks that detect vulnerable software and block devices from authenticating to their company’s cloud apps until they’ve installed the patch.
Our system is based on end users remediating problems themselves (instead of relying on forcing changes), and it’s very effective at enforcing patches, but we don’t write a new check every time we hear about a new vulnerability. Instead, we assess it based on the following questions:
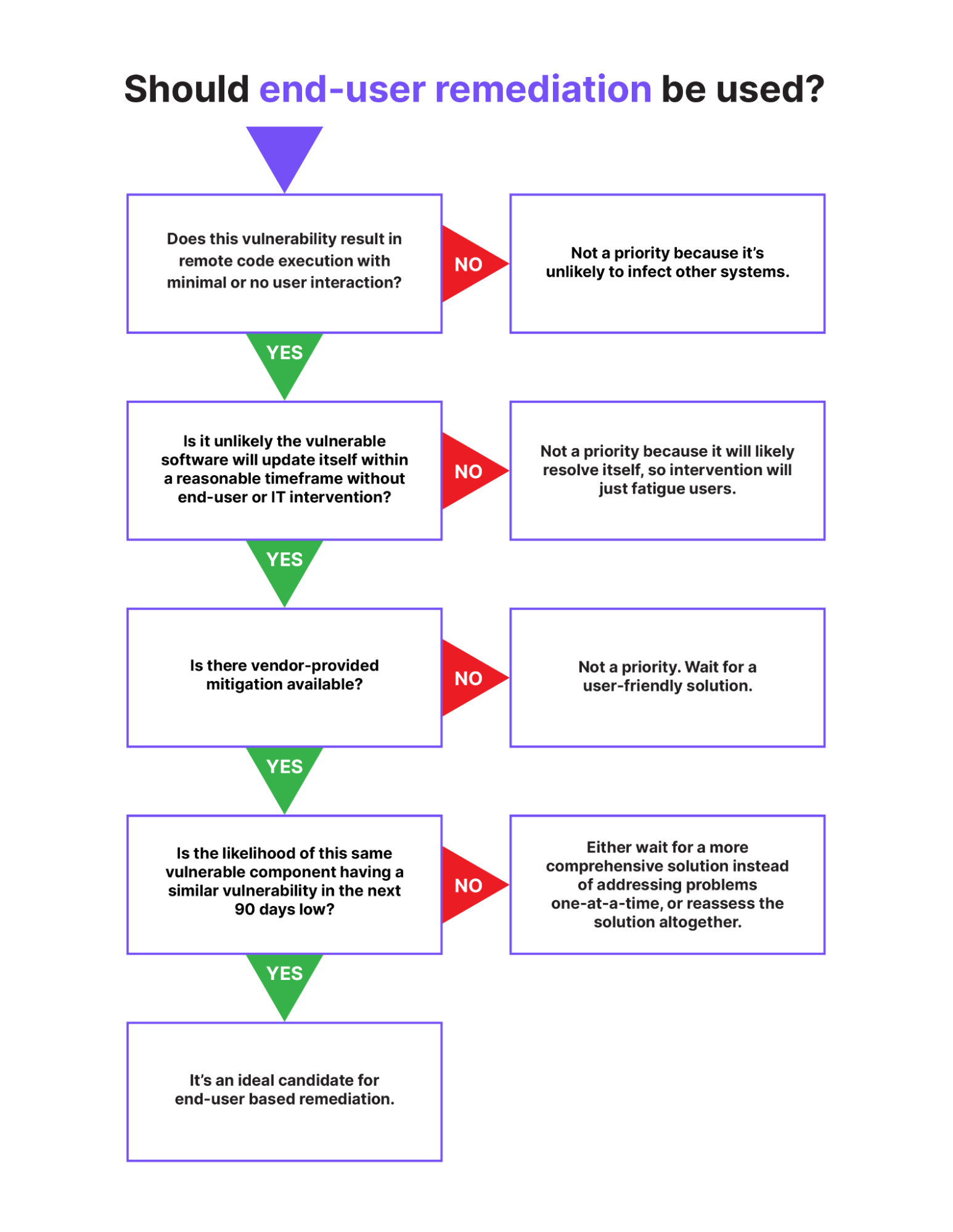
This isn’t a universal method, but it’s a good approach for triaging the vulnerabilities best suited for end users to deal with. (Also, it should be noted that it doesn’t apply to browsers, which are so critical that they are worth bypassing these questions and pinging end users about.)
No consequences for unpatched devices
The chief danger of an unpatched endpoint is that it is infectious. In a typical cyberattack, the bad actor will use a single vulnerability to gain a toehold on a device, then leverage it to move laterally between systems, deploying keyloggers and the like to steal credentials and gain access to more resources. A central tenet of Zero Trust security is to assume that a hacker has already infiltrated your network and act accordingly, by limiting their lateral movements.
There’s an obvious solution here: prohibit devices with critical vulnerabilities from accessing sensitive resources. Yet most patch management solutions don’t have the ability to enforce their policies, so users who (for whatever reason) weren’t included in the automated update can continue to work without interruption. In SMBs, IT can individually reach out to these users, but once we’re talking about thousands of devices, that approach becomes untenable.
Inadequate patch management tools
None of the issues we’ve just gone through would be serious problems if there were an automated solution that could consistently search for and deploy new patches across an organization’s fleet. But while there are plenty of vendors who claim to do precisely that, they all fall short in some way.
MDMs are the go-to patch deployment solution for most IT teams, but that means they come with all the problems mentioned above. Disruptive restarts? Check. Long lists of exemptions? That’s them. MDMs are frequently rigid and offer little flexibility in patch management policy for IT or security teams, much less users. While first-party MDMs like Microsoft Intune and Apple Business Essentials do a pretty good job managing those endpoints, you then have to have separate solutions for a cross-platform fleet (which makes it extremely difficult to have a single source of truth).
Oh, and none of them work on Linux endpoints. Just full stop.
There are also a host of dedicated patch management tools, some of which offer a great deal of flexibility in how IT teams design workflows, such as writing custom scripts and accounting for time zones in their deployment schedule. Still, even the best of them struggle to keep up with the constant deluge of new patches. (It doesn’t help their credibility that many of them claim to support thousands of applications, but the bulk of them are just separate versions of a single application.) Also, none of them provide consequences for unpatched devices, so the work of enforcement gets passed back to IT.
A User-First Approach to Patch Management
The problem at the heart of patch management is that these tools (and frequently the IT and security teams who use them) want to cut users out of the equation. Go to the website of any patch management tool and you’ll see them promise to work “invisibly,” “silently,” or “without any need for user interaction.”
But if the patch management problem could be automated out of existence, it would have been already. Instead, it’s led to devices that are so over-managed they’re difficult to use, while non-managed devices are invisible and out of scope.
Kolide is an endpoint security company that works with users to keep their devices compliant, and ensures noncompliant devices can’t access sensitive resources. (We made a very cool video about it if you’d like to learn more.) Patch management isn’t the only thing our product does, but it is one of our most popular use cases.
This is how Kolide solves patch management:
-
Preserve user agency.
No user likes it when their device is suddenly out of their control. So instead of relying on forced reboots, Kolide reaches out to users with remediation instructions, so they can solve problems themselves, at a time that works for them. This approach lets us solve issues that can’t be solved with automation alone, including patch management on Linux endpoints. -
Ensure unpatched devices can’t access company apps.
As we mentioned earlier, a key idea of Zero Trust security is that if a device isn’t healthy, it isn’t permitted to access company resources. So devices that fail Kolide’s checks can’t log into their Okta-protected apps. That doesn’t mean users are immediately locked out; IT decides how much of a grace period to give. But if a device is missing critical patches (like for an OS or browser) that can mean getting a fully patched fleet in hours. -
Educate users. (Really.)
Every time Kolide notifies users about an issue–whether it’s from our library of checks or one that IT writes with our custom check editor– the notification gives context for why this issue matters, and its potential impact on both security and privacy.
Here’s what all that looks like in (mostly) real time.